NEW documentation: This article covers setup for OWOX BI. For the latest guides on setting up FREE connectors and Data Marts, visit the new OWOX Data Marts documentation.
Between June 11 and 15, pipelines Mandrill→BigQuery, AppsFlyer→BigQuery, and SparkPost→BigQuery will be moved to partitioned tables.
To keep getting relevant reports based on the data from these pipelines, we urge you to prepare new queries for reports that use these pipelines’ data and get ready for the changes until June 11.
What partition tables are
A partitioned table is a special table that is divided into segments, called partitions, that make it easier to manage and query your data. By dividing a large table into smaller partitions, you can improve query performance, and you can control costs by reducing the number of bytes read by a query.
There are two types of table partitioning in BigQuery:
- Tables partitioned by ingestion time: Tables partitioned based on the data's ingestion (load) date or arrival date.
- Partitioned tables: Tables that are partitioned based on a TIMESTAMP or DATE column.
Previously, for processing data for several days in the tables divided by days, you had to use table wildcard functions (TABLE_DATE_RANGE). Now, with partitioned tables, you need to specify the PARTITIONTIME value in your query to process data.
Read more about the queries to partitioned tables in the Google BigQuery documentation.
The benefits of moving to partitioned tables
- Table partitioning lets you specify the queried table fields by the exact hour, minute etc. The query won’t have to process data in the table for the whole day.
- It’s much easier to update and delete the table data. Since DML queries can be applied to only one table at a time, you had to query each table separately. With table partitioning, you store all data in one table, so you can use a single query to manipulate any data you need. This also will help you easily delete or anonymize user data to comply with the GDPR requirements.
How exactly the changes in the pipelines will happen
Between June 11 and 15, we will create the new partitioned tables for the Mandrill, AppsFlyer, and SparkPost pipelines. From that moment, all data in these pipelines will be sent to partitioned tables instead of the tables divided by days.
The names of the new partitioned tables will be the same as of the tables divided by days.
The tables will be partitioned by the time the data was written to the table. This time may differ from the actual time of the event and from the time the event was sent from the data source service.
Historical data from the old tables will be copied to the new partitioned tables, divided by days. After that, we will delete all the old tables.
All historical data will be copied to the new tables within one week after the pipelines start collect data into partitioned tables.
Important: Start using new queries only after all your historical data is copied.
How will the changes affect data processing
The structure of BigQuery tables will not change. The tables you get as the results of the SQL queries will not change either.
The only thing you need to change in your queries is the method of selecting the date range. While previously, you have been using FROM TABLE_DATE_RANGE(...), in partitioned tables you need to use the WHERE PARTITIONTIME > AND < (BETWEEN) condition.
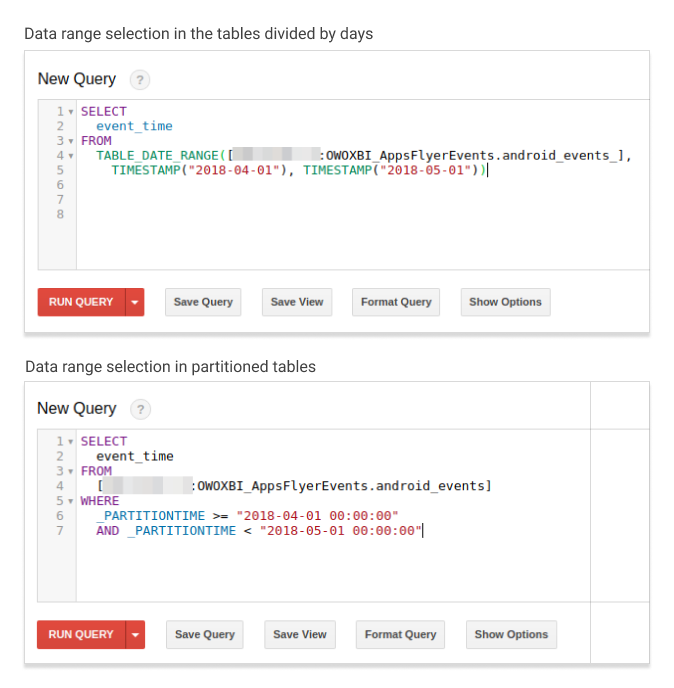
Since partitioned tables are divided by the time data was added, data volumes collected per day can slightly—by seconds—differ compared to the previous table division method.
For example, non-partitioned AppsFlyer tables are divided by days based on the event_time field value. In partitioned tables, the division into partitions is based on the time the entry was added to the table. Thus, in some cases, the time values in these two fields may differ. The events sent near the end of the day may get into the partition with another event_time value.
If you have any questions regarding partitioned tables, write us at bi@owox.com. We’ll be happy to answer :)
0 Comments